版权声明:本文为博主原创文章,未经博主允许不得转载
XCode编译速度提升
由于之前在Mac mini上开发过一段时间,所以对于编译速度提升还是比较重要的(编译一次半个小时了解一下)。这里整理了一下通过修改Xcode配置来提升编译速度的的方法,增量编译等暂不讨论。
序、xcode编译过程
1、预编译pch文件(如果有的话) 2、编译各种资源文件 3、copy静态资源 4、compile asset catalogs 5、process info.plist 6、link 7、生成 dsym文件 8、sign app
如果要优化编译速度,基本上就是从以上几点着手,本文从1、3、4、5、6、7这几点开始,优化编译速度。虽然现在xcode自带了增量编译,但是每次clear后重新编译的时候,还是会要耗时很久(经历过Mac Mini的人应该深有体会)
开启编译耗时显示
打开终端执行defaults write com.apple.dt.Xcode ShowBuildOperationDuration YES 重启Xcode
一、编译时长优化 Find Implicit Dependencies
对所编译项目的Scheme进行配置 Product > Scheme > Edit Scheme > Build Build Opitions选项中,去掉Find Implicit Dependencies.
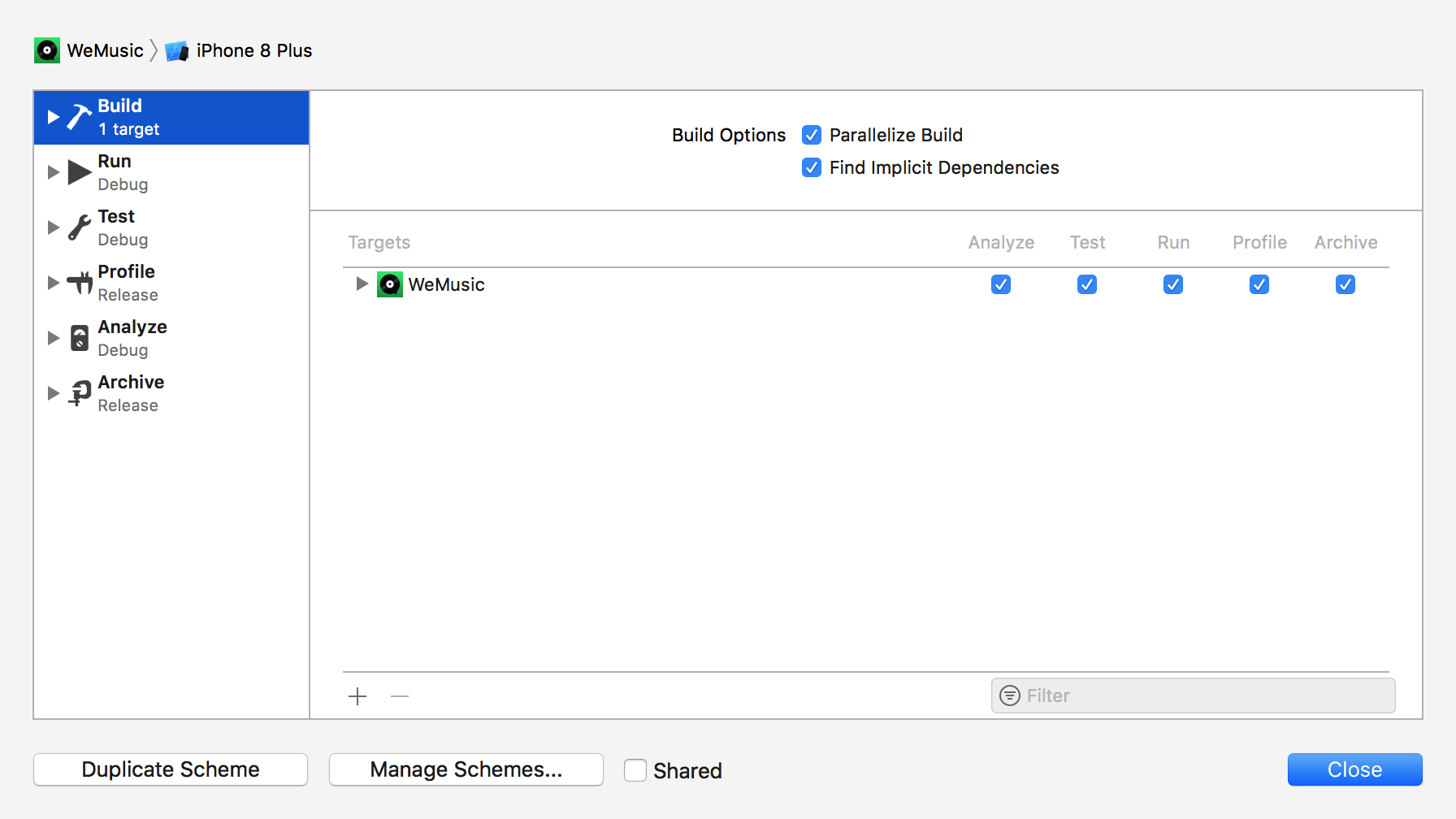
原理: 选中Find Implicit Dependencies时,编译以下内容: * 项目所有的文件 * 被修改的frameworks文件
未选中Find Implicit Dependencies时,编译以下内容: * 项目中必要的文件 * 不会重新编译frameworks文件,即时你对其中的文件做了修改
Test: 对不同设置下(是否选中Find Implicit Dependencies)的项目编译时间进行比较。 注:每次编译前 进行clean操作(shift + command + k),达到消除Xcode自身增量编译带来的干扰。
缺点分析:
在这个选项(Find Implicit Dependencies)被选中的情况下,即使你只是对项目进行了很细微的
改变,项目中的所有资源文件都会被重新编译一遍。也会对所有被改变的frameworks进行编译。没有选
中这个选项时,只会对文件中的一些OC文件进行编译,编译耗时会显著的下降。只是,在这种模式下,
你对frameworks中的文件所进行的修改将不会进行重新编译。
结论:
视修改的项目文件的不同,对两种Scheme进行选择,择一使用以提高编译性能。
二、编译时长优化 Architectures
在Build Settings中,有个Architectures配置选项。
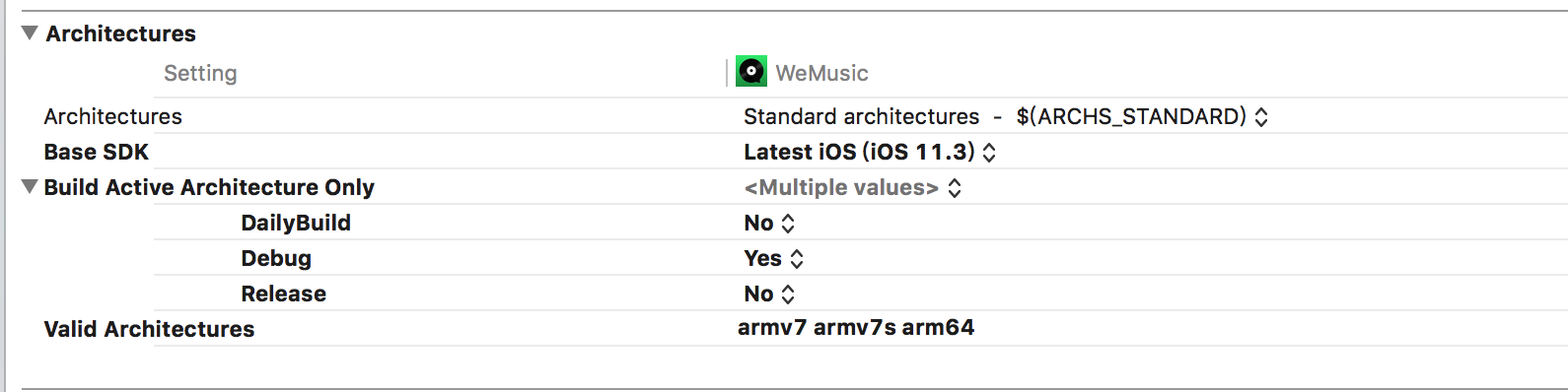
Architectures 是指定工程支持的指令集的集合,如果设置多个architecture,则生成的二进制包会包含多个指令集代码,提及会随之变大。
Valid Architectures 有效的指令集集合,Architectures与Valid Architectures的交集来确定最终的数据包含的指令集代码。
Build Active Architecture Only 指定是否只对当前连接设备所支持的指令集编译,默认Debug的时候设置为YES,Release的时候设为NO。Debug设置为YES时只编译当前的architecture版本,生成的包只包含当前连接设备的指令集代码;设置为NO时,则生成的包包含所有的指令集代码(上述的V艾力达Architecture与Architecture的交集)。所以为了更快的编译速度,Debug应设为YES,而Release应设为NO。
注:Debug设置为YES时,如果连接的设备是arm64的(iPhone 5s,iPhone 6(plus)等),
则Valid Architecture中必须包含arm64,否则编译会出错。这种模式下编译出来的版本是向下
兼容的,即:编译出的armv6版本可在armv7版本上运行。
三、编译时长优化 Precompile Prefix Header 预编译头文件
Build Setting > Apple LLVM 7.1 - Language
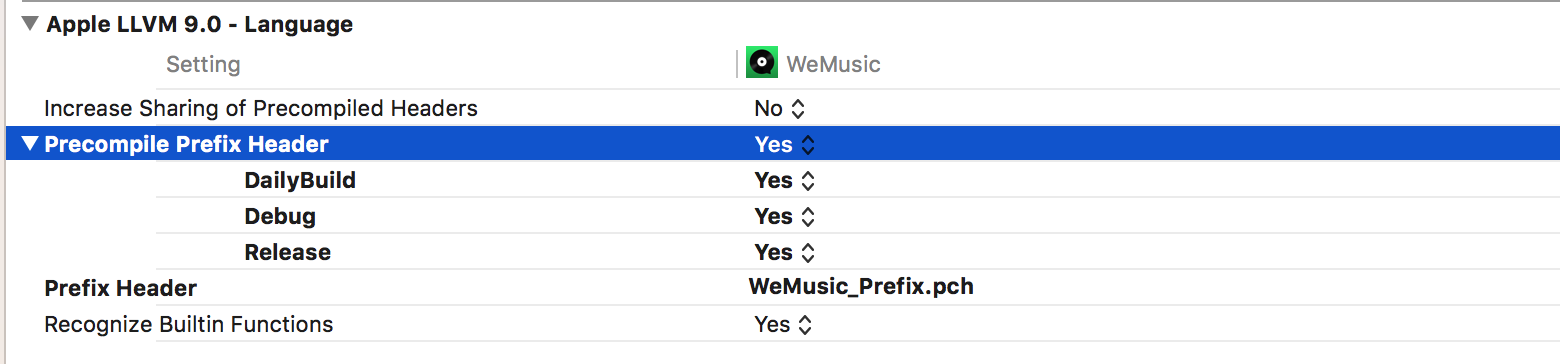
Xcode 6及之后版本默认不使用pch文件参与项目编译,原因有二: * 去掉自动导入的系统框架类库的头文件们可以提高源文件的复用性,便于迁移; * 一个庞大的Prefix Header会增加Build耗时。
但对于原有项目应用了pch文件的情况,就需要对Xcode的Build Setting进行配置以使用pch。
当Precompile Prefix Header设为NO时,头文件pch不会被预编译,而是在每个用到它导入的框架类库中编译一次。每个引用了pch内容的.m文件都要编译一次pch,这会降低项目的编译速度。
将Precompile Prefix Header设为YES时,pch文件会被预编译,预编译后的pch会被缓存起来,从而提高编译速度。 需要编译的pch文件在Prefix Header中注册即可。
四、编译时长优化 Compile - Code Generation Optimization Level
Build Setting > Compile - Code Generation > Optimization Level
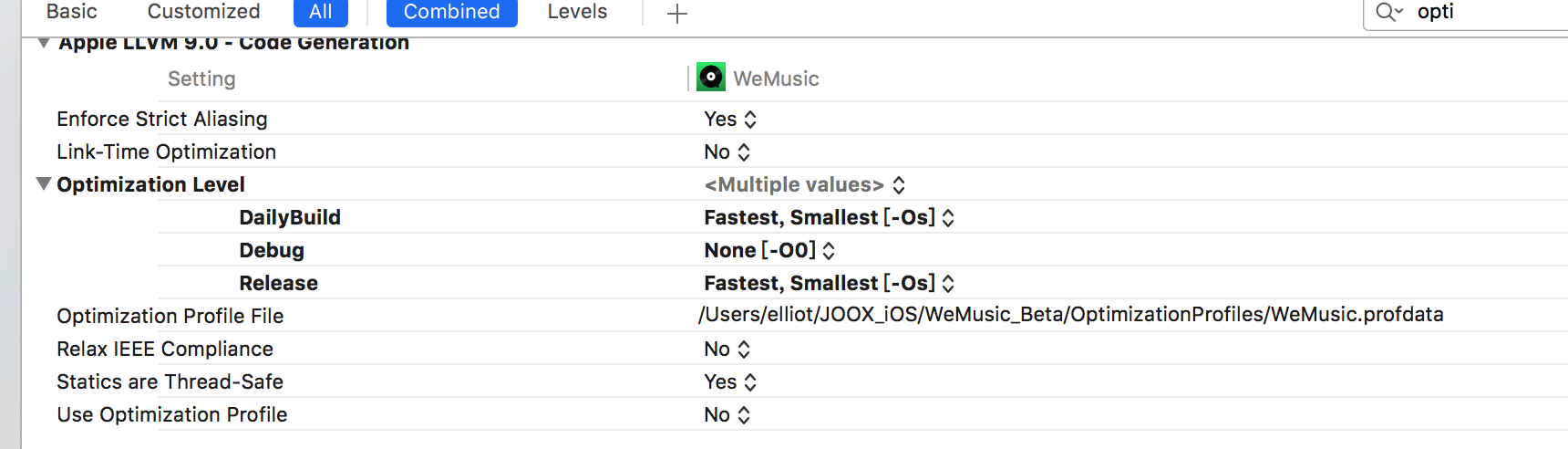
Debug None[-Onone] Release Fast[-O] 是Xcode在Debug模式下编译项目的最优选项,通过测试可以看出,在默认配置情况下和自定义情况下的编译耗时存在比较明显的差异。
注意:在设置编译优化之后,XCode断点和调试信息会不正常,所以一般静态库或者其他Target这样设置。
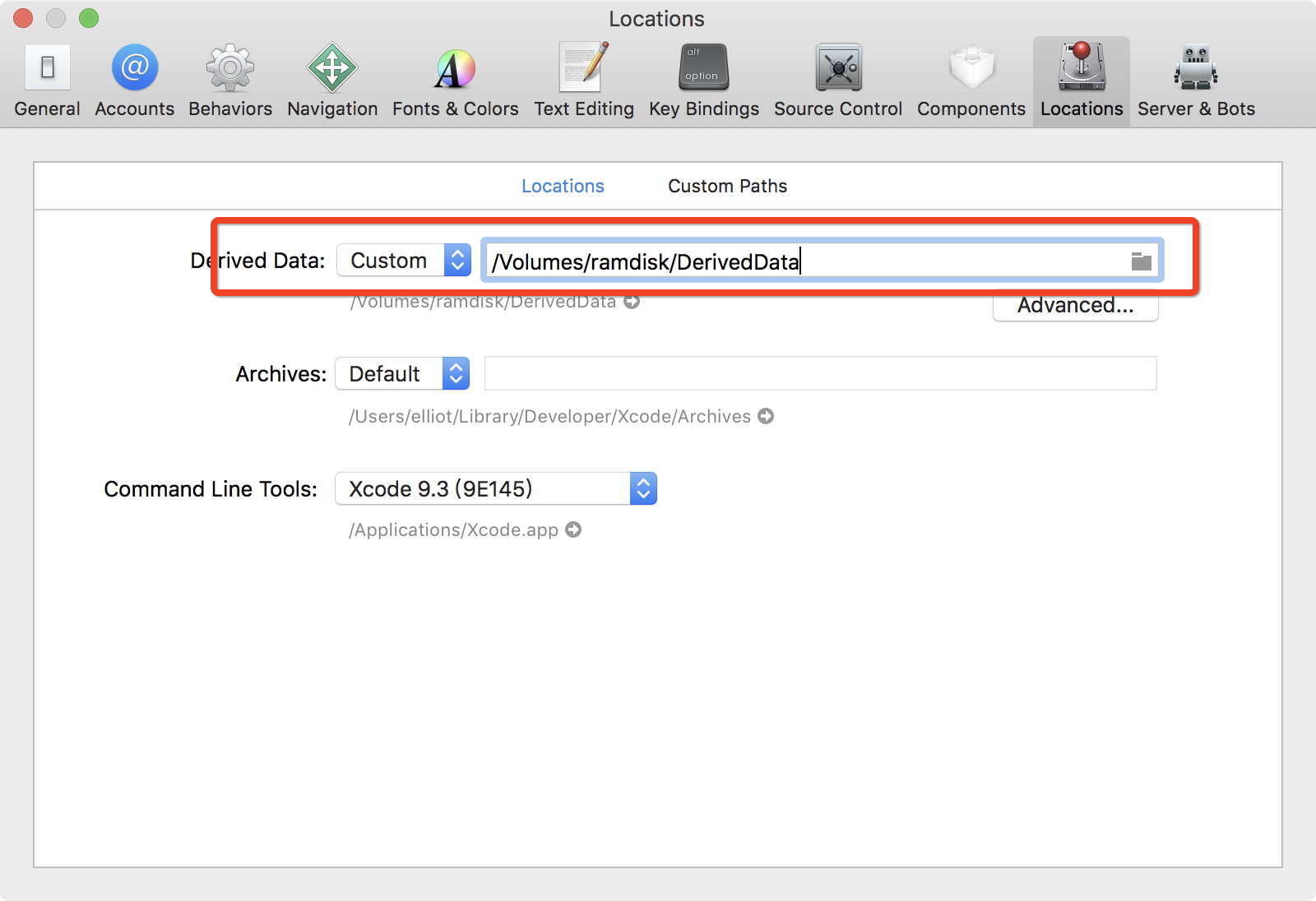
五、加载RAM磁盘编译Xcode项目
DerivedData
Xcode会在文件系统中集中的缓存临时信息。
每次对Xcode iOS项目进行clean、build或者在iOS虚拟机上launch,Xcode都会在DeriveData文件夹中进行读写操作。换句话说,就是将Derived Data的读写从硬盘移动到内存中。 DeriveData文件夹中包含了所有的build信息、debug- 和 release- built targets以及项目的索引。当遇到零散索引(odd index)问题(代码块补全工作不正常、经常性的重建索引、或者运行项目缓慢)时,它可以有效地删除衍生数据。删除这个文件夹将会导致所有Xcode上的项目信息遭到破坏。
Step 1
将DeriveData下的文件删除:
rm -rf ~/Library/Developer/Xcode/DerivedData/*
hdid -nomount ram://4194304
删除的这些数据,Xcode会在Build时重新写入的。
Step 2
在~/Library/Developer/Xcode/DerivedData.上部署安装2 GB大小的RAM磁盘。 进到~/Library/Developer/Xcode/DerivedData.
cd ~/Library/Developer/Xcode/DerivedData
创建2 GB的RAM磁盘(size的计算公式 size = 需要分配的空间(M) * 1024 * 1024 / 512):
hdid -nomount ram://4194304
此行命令后将会输出RAM磁盘的驱动名字:/dev/diskN(N为数字)。
初始化磁盘:newfs_hfs -v DerivedData /dev/rdiskN
有以下输出:
Initialized /dev/rdisk3 as a 2 GB case-insensitive HFS Plus volume
安装磁盘:diskutil mount -mountPoint ~/Library/Developer/Xcode/DerivedData /dev/diskN
这会在已存在的DeriveData上安装一个卷,用于隐藏旧的文件。这些文件仍会占据空间,但在移除RAM磁盘之前都无法访问。
在重启或从Finder中弹出RAM磁盘时,磁盘中的内容将会消失。下次再创建磁盘时,Xcode将会重新构建它的索引和你的项目中间文件。
创建虚拟磁盘后, 并不是直接占用掉所有分配的空间, 而是根据虚拟磁盘中的文件总大小来逐渐占用内存. 注:如果创建的虚拟磁盘已满, 会导致编译的失败. 此时清除掉Derived Data后重新编译, 就算有足够的空间也还是有可能会导致编译失败. 重启Xcode可以解决此问题.
对手头Demo进行编译测试,由于编译本身读写内容较少,耗时较短,都在10s到20s之内,所以提速感觉不明显,在1s到2s间(10%左右),也许应用到较大的项目中会有比较好的体现。
六、编译线程数和Debug Information Format
6.1、 提高XCode编译时使用的线程数
defaults write com.apple.Xcode PBXNumberOfParallelBuildSubtasks 8
其后的数字为指定的编译线程数。XCode默认使用与CPU核数相同的线程来进行编译,但由于编译过程中的IO操作往往比CPU运算要多,因此适当的提升线程数可以在一定程度上加快编译速度。
6.2、 将Debug Information Format改为DWARF
在工程对应Target的Build Settings中,找到Debug Information Format这一项,将Debug时的DWARF with dSYM file改为DWARF。

这一项设置的是是否将调试信息加入到可执行文件中,改为DWARF后,如果程序崩溃,将无法输出崩溃位置对应的函数堆栈,但由于Debug模式下可以在XCode中查看调试信息,所以改为DWARF影响并不大。
需要注意的是,将Debug Information Format改为DWARF之后,会导致在Debug窗口无法查看相关类类型的成员变量的值。当需要查看这些值时,可以将Debug Information Format改回DWARF with dSYM file,clean(必须)之后重新编译即可。
七、Link-Time Optimizations 链接时优化
Apple LLVM 7.1 - Code Generation Link-Time Optimization
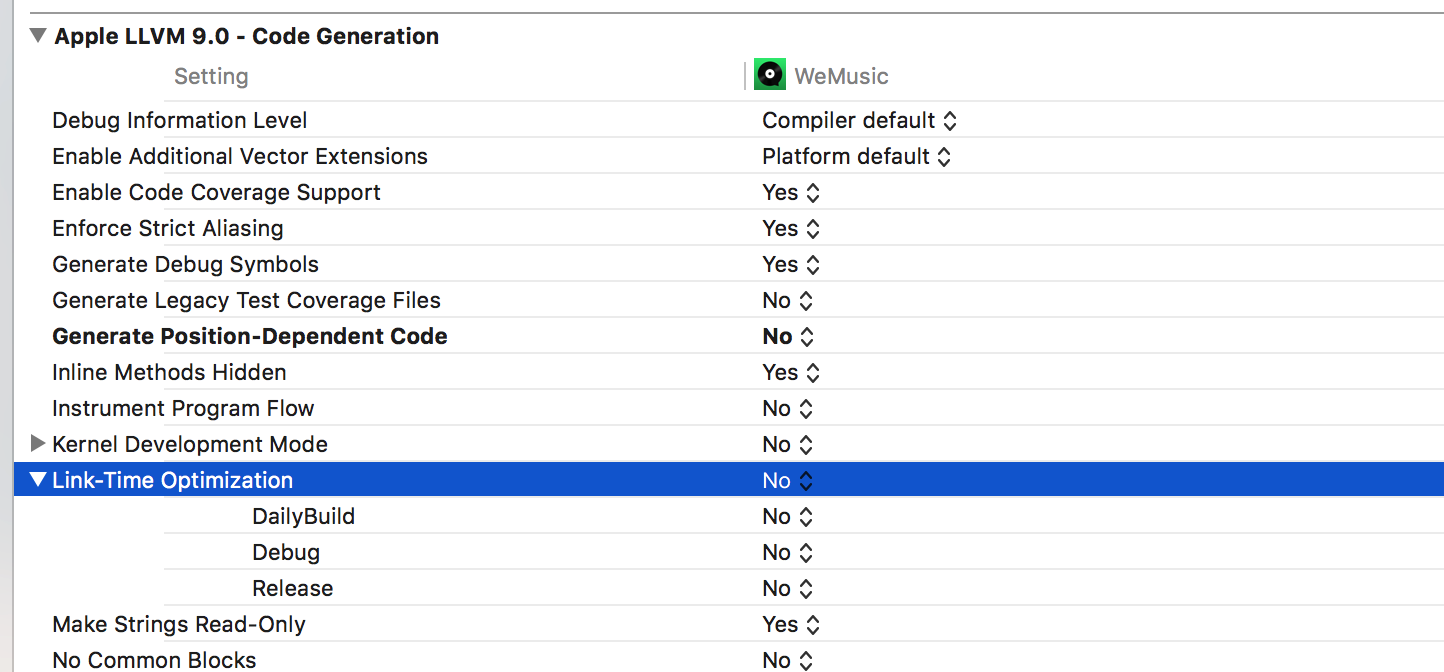
Link-Time Optimization执行链接时优化(LTO)。在Clang/LLVM领域,这意味着链接器获得的是LLVM字节码,而不是通常的目标文件。这些字节码在一种更抽象的层次上代表程序这里写链接内容的执行过程,允许LTO得以进行,但是坏处是,仍然需要将他们转换成机器代码,在链接时需要额外的处理时间。
参数设为YES时,能够优化链接时间;目标文件以LLVM二进制文件格式存储,在链接期间,优化了整个程序。
将其设为NO时,可以减少Link阶段的时间。对于Link阶段耗时较长的项目,整体编译优化体现较为明显。
八、加装SSD固态硬盘
固态硬盘传输速度能达到500MB/s,其中读取速度达到400-600MB每秒,写入速度达到200MB每秒。而传统硬盘读取速度极限也无法超越200MB每秒,写入速度在100MB每秒左右。如果遇到非连续的散片数据,SSD能体现出极快的读写速度。而传统机械硬盘由于磁头寻道等原因,传输速度偏慢。
九、安装包大小优化 Asset Catalog Compiler - Options Optimization
Build Setting > Asset Catalog Compiler - Options
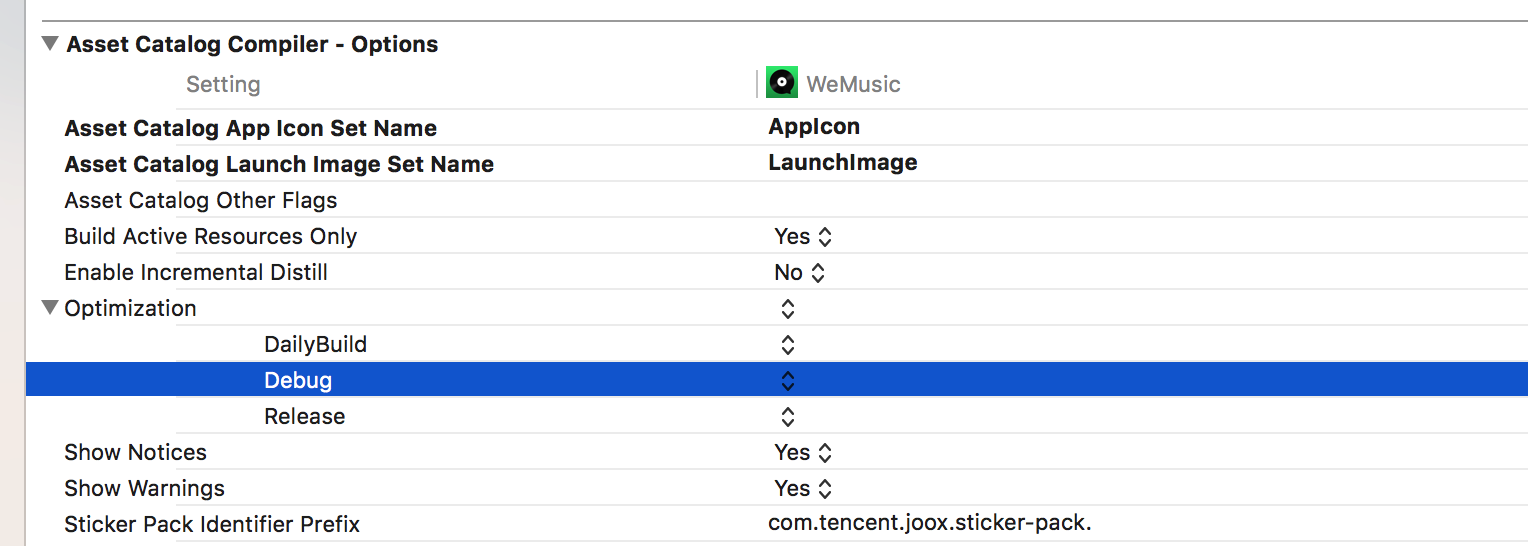
在Optimization 优化设置项有三个选项,不指定、time和Space。
Optimization nothing是Xcode默认的设置。 与预想的不同,在选择Optimization time 时,编译时长并没有得到优化。 但在Optimization space时,编译耗时基本没有波动,但编译生成的app 大小有不小程度的优化。
十、安装包大小优化 Flatten Compiles XIB Files
是否扁平化编译XIB文件。
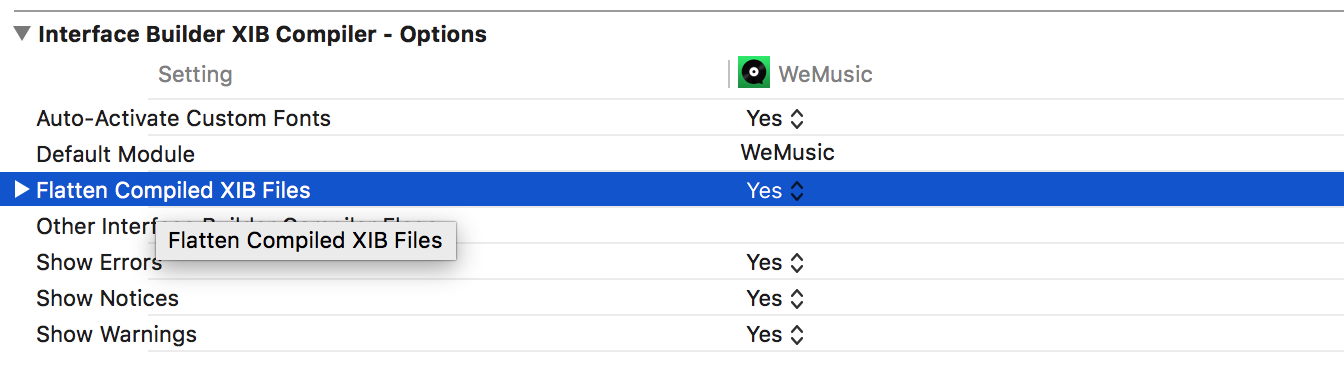
官方解释是:指定是否在编译时剥离nib文件以优化它们的大小,设为YES时编译出来的nib文件会被压缩但是不能编辑。
Description: Boolean value. Specifies whether to strip a nib files to reduce their size. The resulting nib file is more compact but is not editable.
测试app大小的同时也对编译耗时进行了测试,在两种编译模式下的编译耗时基本没有变化。
十一、安装包大小优化 清理未被使用的图片资源LSUnusedResources
略。
十二、安装包大小优化 Deployment Postprocessing和Strip Linked Product
Xcode中Strip Linked Product 的默认设置为YES,但是Deployment Postprocessing的默认设置为NO。在Deployment Postprocessing 是Deployment的总开关,所以在打开这个选项之前 Strip Linked Product是不起作用的。

注:当Strip Linked Product设为YES的时候,运行app,断点不会中断,在程序中打印[NSThread
callStackSymbols]也无法看到类名和方法名。而在程序崩溃时,函数调用栈中也无法看到类名和方法名。
十三、安装包大小优化 Linking->Dead Code Stripping
将Dead Code Stripping 设置为YES 也能够一定程度上对程序安装包进行优化,只是优化的效果一般,对于一些比较小的项目甚至没有什么优化体现。
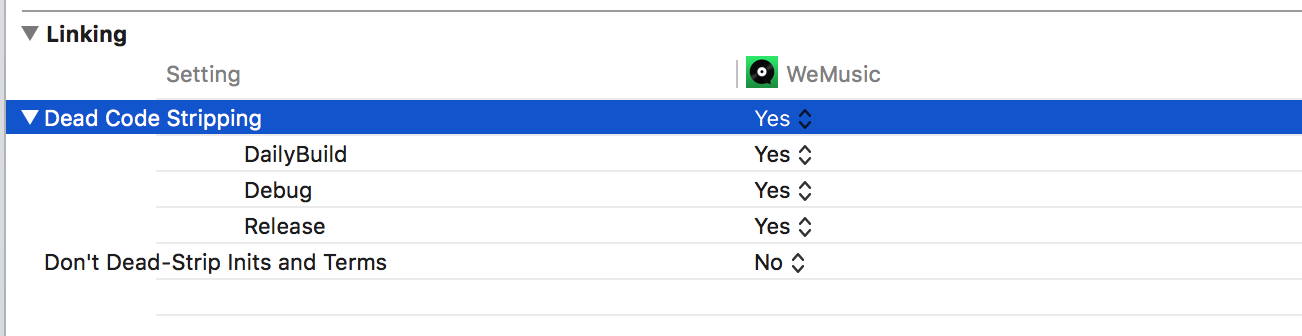
Dead Code Stripping 是对程序编译出的可执行二进制文件中没有被实际使用的代码进行Strip操作。
十四、使用新的XCode build方式
File菜单 -> Working space Building System -> New Building System(Preview)
 测试了大概优化了8s左右
测试了大概优化了8s左右
测试设备: MacBook Pro (Retina, 15-inch, Mid 2015) 2.2 GHz Intel Core i7 4核 16 GB 1600 MHz DDR3 实际测试效果
| 配置修改 | 现有配置 | 修改DWARF | 其他配置修改 | 加载RAM | 使用new Build |
| 3次测试平均耗时 | 210s | 197s | 191s | 181s | 172s |
编译速度提升18%左右,其中主要优化项为:修改DWARF、加载RAM、使用new Build。
结论:编译速度优化最主要的是靠硬件,通过修改配置来优化编译速度总是有限的。